
BFCM 2025 - A Magical time for Shoppers, Merchants and Engineers
How we kept our systems healthy at 1 Million+ RPM


You’ve just had a wonderful thanksgiving dinner, you hit the bed early, and as soon as you wake up, you must be prepared for one of the biggest sales of the year! BFCM, Black Friday - Cyber Monday, is one of the most important periods on the commerce calendar, with an ever-growing YoY revenue.
When most folks were getting ready to buy all your favorite products, at Swym we took this chance to display our ability and engineering excellence at scale.
This was our 10th BFCM at Swym, poised to be the biggest BFCM yet. We onboarded a lot of merchants BFCM’24, but we were also the most prepared this year. We moved all of our services to better infra and improved a lot of our infra practices - we handled 1 Million+ RPM with low turbulence, almost like a breeze, if we daresay.
Here is a quick recap of what we enabled BFCM 2025 for our merchants
This post is the story behind how we engineered this BFCM at Swym.
Let’s divide and conquer the process, we had multiple focus areas that we worked on to make our systems ready for BFCM, we cover them one by one.
Migrating to Kubernetes
Kubernetes was a huge thing in Swym, we were using it for all our queue processors and NodeJS Services, but the bulk of our ecosystem was written in Clojure and they were still on VMs.
During BFCM 2024, we had to provision new VMs and do some capacity planning to make sure we didn’t go down under the BFCM load, but this January this year we realized that we have had enough of this manual provisioning (We used Terraform, but still, it was too slow), so we decided to move our Clojure (pseudo) microservices to Kubernetes as well. (If you are asking Why Clojure? 🤔)
A 2-month long consistent effort was required to onboard all our services to Kubernetes. Every service we onboarded presented its own problems. For example, our Clojure Services presented had some statefulness in them, we had to rewrite the stateful parts of the service to make them stateless. There were also changes in the way configuration was loaded into the services, eg: Clojure services used EDN files for configuration (a Clojure native data notation), which wasn’t the case in NodeJS services.

But in the end after we fixed all the bugs, we saw light at the end of the tunnel, the K8s Migration was complete and our microservices were autoscaling.
We tuned the autoscaler according to our needs and waved a fond Goodbye to the days of manual VM creation and management.
Observability Overhaul (Prometheus, Jaeger, OpenSearch fixes)
When you receive 800-900K requests per minute, you generate 2 to 4 times the amount of logs and traces. We were processing at least 3000 spans per second and about 80-100GB of logs per hour, pre-BFCM. The scale like we anticipated spiked during BFCM.
Logging
Our logging architecture had to improve exponentially to handle this scale. We shifted from logstash to a fluentbit-fluentd based agent-aggregator architecture, for the log collection mechanism.
Fluentbit pods (agents), running as a part of a daemonset collected the logs from the services and just forwarded (using the fluent forward protocol) them to the Fluentd aggregator. The Agents ran as daemon-sets in their respective nodepools. You can configure a daemonset to run only on a specific set of nodes by setting node affinity.
The Fluentd aggregator decided which index on OpenSearch to push the logs to, using an custom Lua Script. This helped us ensure that none of the logs were lost
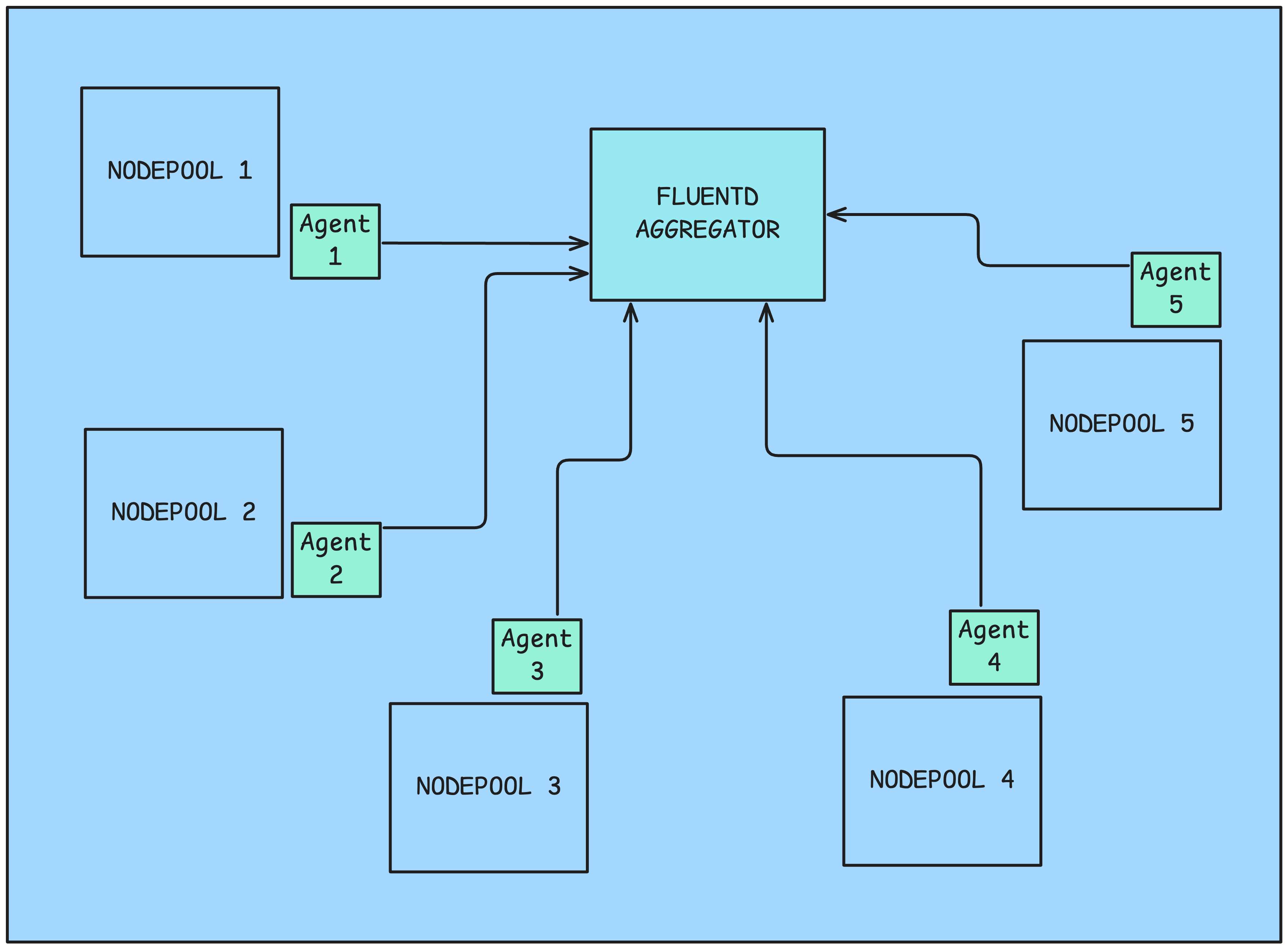
OpenSearch created the indices and maintained them using ISM (Index State Management) policies, which were used to configure log retention and priority, thus keeping storage costs and maintenance manageable.
Tracing
Jaeger is the absolute core of our debugging workflow—losing spans or a Jaeger outage during BFCM would be equivalent to operating blind. Our previous setup wouldn’t cut it, demanding a much more resilient cluster and an upgrade to Jaeger V2.
To future-proof the system, we introduced redundancy:
Services push spans to OpenTelemetry (Otel) Collectors.
Otel Collectors push the spans into a temporary Kafka buffer (our “Kafka-Span-Buffer”).
Otel Kafka Consumers read the spans and write them to OpenSearch.
This Kafka buffer was designed to prevent span loss during temporary downstream issues. However, the sheer write load exposed a major bottleneck: the underlying hard disks (HDDs) reached maximum throughput, causing critical latency spikes.
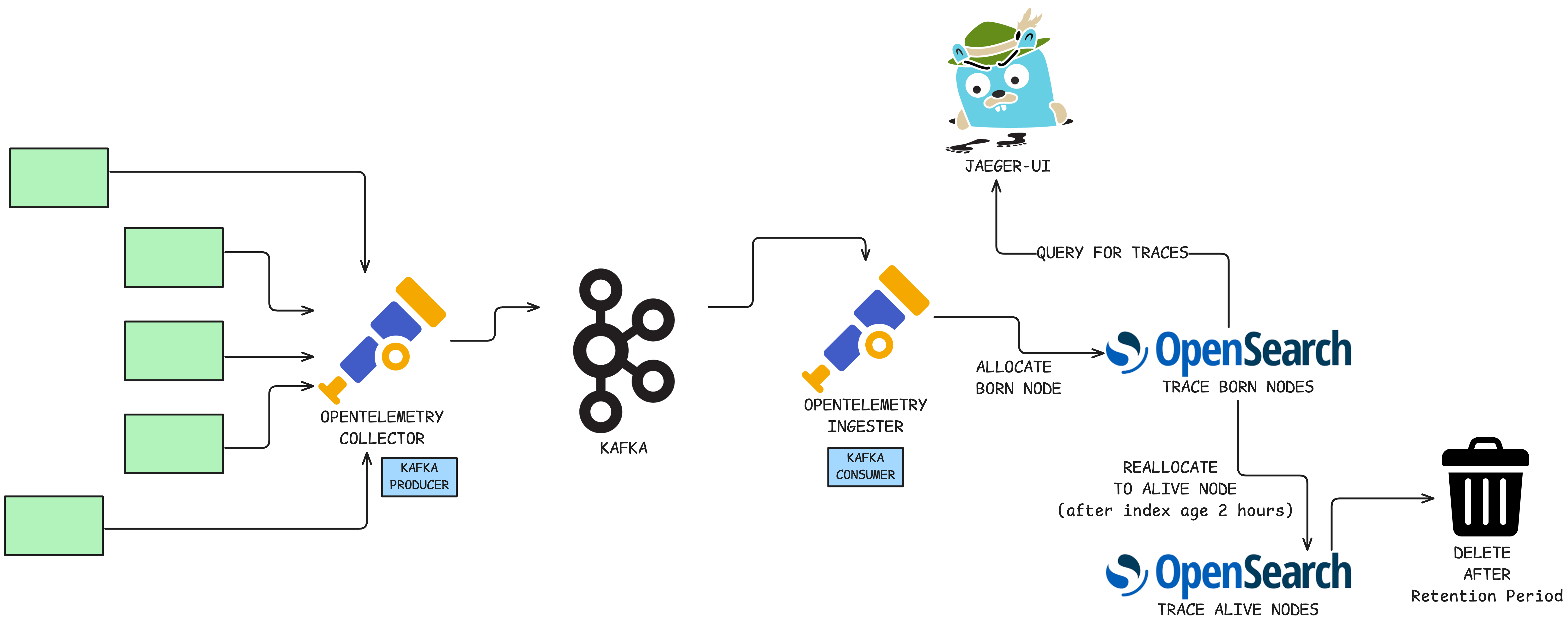
The Fix: We immediately provisioned a high-performance SSD dedicated exclusively for the primary write index in OpenSearch. After a brief, high-throughput period (e.g., one hour), the index would automatically roll over, and the data stored on the expensive SSDs was migrated to a low-performance archival node. This tactical use of hardware ensured zero write latency during peak traffic periods, while keeping the costs low.
This way we were able to process and save 2.5 billion+ spans during the 4 days of BFCM.
JVM Optimization
Obvious but requisite context - Java compiles to byte code and the byte code runs on the Java Virtual Machine, which in-turn runs on bare metal. This makes Java a versatile and cross-platform programming language. Fun fact, though its heavy, it is faster (comparable to C or C++) when it comes to runtime on a single core CPU. This is because the JVM optimizes your byte code multiple times during runtime. It generates hotpaths for frequently executed code. The JVM can be tuned to give max performance. We missed a very important JVM flag when migrating our services to kubernetes! This caused our services to severely under utilize the available memory.
We had forgotten the MaxRAMPercentage Flag and JVM was defaulting to 25% 🫠 🫠 🫠 !!!
Relearning that from our VM-based deployments quickly, the memory utilization of our VMs became extremely optimal after setting it to 75% and this one flag gave us a lot of perf gains including a significant ART reduction (190-300ms across our services) and a good fistful of dollars saved per hour!

Pro tip - JVM Flags are critical, if someone tells you otherwise, they’re probably C# developers 😉.
I cannot do justice to this finding in such a short paragraph, let me explain the different JVM flags we use and why, in a separate post.
Queue Processor Optimization
A major design choice in our VMs was, the service that was serving API requests was also tasked with processing messages across queues.
The tight coupling of real-time API serving and asynchronous queue processing was a major part of our original VM architecture. While it was manageable at a lower scale, this mixing of responsibilities was inefficient and prevented us from maximizing resource utilization. While separation of concerns sounds like an obvious answer that you would get most engineering minds nodding in agreement, the reality of maintaining more sub-systems for little-to-no-value is something we take seriously. Hence the “why” we need to do it had to go into first principles alignment without throwing the proverbial baby with the bath water.
The Decoupling Strategy
To solve this and fully leverage our Kubernetes migration, we implemented a complete separation of concerns:
API Services: Responsible only for handling synchronous, user-facing requests and pushing asynchronous work onto the queue. These services require high availability and predictable performance.
Queue Processors: Responsible only for consuming messages from the queue and executing short-lived, asynchronous tasks. These services can tolerate disruption and have variable capacity needs.
Leveraging Azure Spot VMs for Cost Optimization
This separation was key to an immediate and substantial cost optimization.
We achieved this by utilizing Azure Spot Virtual Machines through Azure Kubernetes Service (AKS) Spot Nodepools:
API Services Deployment: These were deployed onto Reserved Instances (standard, high-availability nodepools) to ensure zero downtime and consistent API performance.
Queue Processors Deployment: These were moved entirely to Spot Nodepools (using Azure Spot VMs). The disruptable nature of Spot VMs—where Azure can reclaim the resource with a short notice—was entirely acceptable for our queue processors, as the queued messages would simply be picked up by another available Spot VM or, if necessary, a reserved VM once it became available.
Azure Spot Virtual Machines, are basically leftover capacity that Azure wants to use in an effective way. Say Azure has 100 Virtual Machines, and it has rented out 30 to Swym and 20 to CompanyX, now, it has 50 unused VMs. Azure offers these under the Spot Category at fraction of the actual price!! But the caveat is that Azure can reclaim these VMs if it needs them for something else, say, CompanyZ wants 50 VMs. Azure gives a 30 second, eviction notice before reclaiming the capacity.
The above explanation is a very crude one, please read more about Azure Spot VMs here.
The practical implementation was simple: we used an environment flag within our application to toggle between the API-serving logic and the asynchronous processing logic. By running these two configurations on different nodepools, we effectively:
Improved API Performance: By dedicating highly available resources solely to low-latency API calls.
Optimized Costs: By running the resource-intensive, interrupt-tolerant asynchronous tasks on highly discounted Spot VMs.
Code Freeze!
There was a strict code freeze during the entire span of the BFCM period, no deployments or config changes were allowed during this period (unless they were bug fixes). To be our own critic - That doesn’t sound like a 2025-ready decision. But we chose to stop deploying any new lines of code without a strong reason that can’t wait for the 5-7 days. This is an area of improvement for 2026, something we keep tinkering on how to enable true CI/CD.
In the meantime, we upgraded our kubernetes clusters, and applied multiple security patches to the existing codebase, further hardening our systems for the impending fun onslaught 😎.

Finally, most of the engineering team (almost all Swymmers are engineers 👩💻👨💻) got together in Bengaluru and kept an eye aka stared at the BFCM Grafana dashboards for days and nights on a shift basis to celebrate every spike and stat that showed how much of the global ecommerce volumes we helped supporting. Thankfully, there were just murmurings of incidents or outages, lots of (welcome) false flags that drove us to finding better ways of monitoring/concluding if a peak/trough was concerning or not.

Conclusion
True to our core values, we hoped for the best but planned for the worst. And thankfully we surged ahead along with the BFCM rush for our merchants — and our engineering held up to the standards we wanted to set for ourselves 🙌.

The shift to Kubernetes turned capacity spikes into non-events, replacing manual firefighting with automated, cost-efficient elasticity that sailed past 1 million+ RPM (repetitive but we are super thrilled 😄). Our Observability Overhaul paid dividends, processing 2.5 billion+ spans and transforming potential blind spots into clear operational awareness and intelligence across teams.
From relearning like the critical JVM MaxRAMPercentage fix to deploying advanced Spot VM cost-optimizations, every strategic move has helped move our platform forward. Our infrastructure is set for the next phase of our growth. We are scaling, optimizing and ready for whatever the next peak 2026 throws our way.
Here are a few episodes from our podcast on pre-BFCM prep and even an episode in the middle of BFCM 🥵 😎
Awesome.
To paraphrase Winston Churchill...never before have so many owed so much to so few!
Keep it up!!