
From 43 Seconds to 3 - How I Optimised My SQL Query to Run 13x Faster
tl;dr - let's not be DISTINCT

Ever stare at a query progress bar, feeling like you could brew a pot of chai (or maybe even two here in Bengaluru!) before it finishes? I’ve been there. Just recently, I hit a wall with a PostgreSQL query that was taking a whopping 43 seconds to run. Annoying, right?
But stick around, because this story has a happy ending - a 3.2-second ending, to be precise! It involves a large table, a seemingly obvious query, a facepalm moment, and a crucial reminder about the fundamentals we sometimes overlook. Whether you're just dipping your toes into databases or you're a seasoned pro, I bet you'll find something useful (or at least relatable) here.
The Mission: Counting Unique User Devices
My task seemed simple enough: In our event_logs table (a beast with over 312 MILLION rows, consuming about 43 GB of disk space!), I needed to find the total number of unique combinations of session_key and user_tag for one specific account_id.
Easy peasy, right? My brain immediately went: "Unique? That's a job for DISTINCT!" So, I proudly typed out something like this:
SQL
-- My "Logical" First Attempt
SELECT
COUNT(DISTINCT (session_key, user_tag)) -- Count unique pairs, right?
FROM
event_logs
WHERE
account_id = 'some_specific_account_id';Looks reasonable, doesn't it? We filter by the account, then ask Postgres to count the distinct pairs of session_key and user_tag. Job done?
The Reality Check: 43 Seconds of Waiting...
I hit 'Run' and... waited. And waited.
(Imagine a clock ticking loudly here... maybe a tumbleweed rolling past)
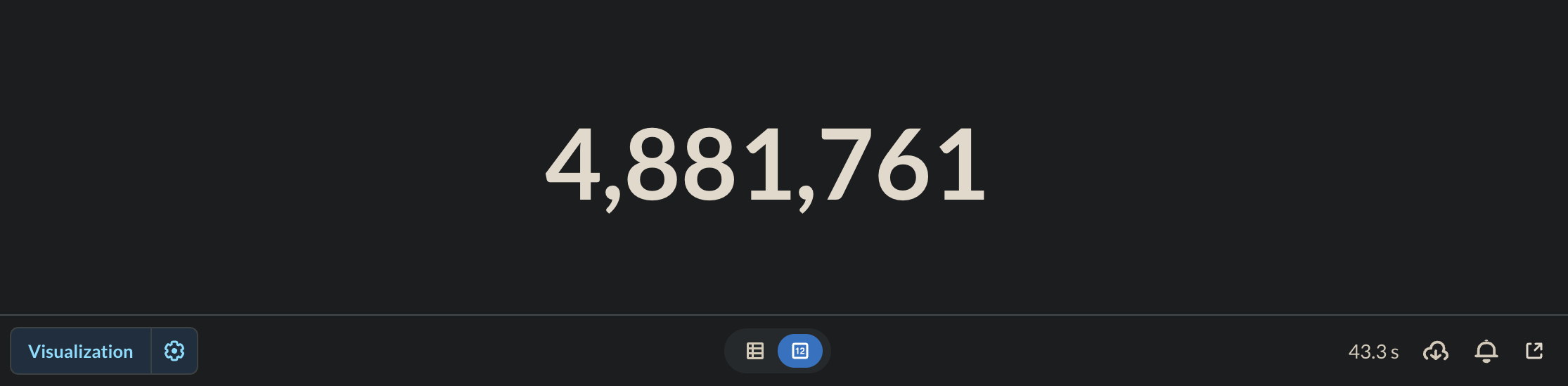
43.3 seconds later, I got my number. Okay, getting the result is good, but over 40 seconds for a count? On a production system, that could feel like an eternity for users or downstream processes. Something wasn't right. The massive table size was obviously a factor, but could it be this slow?
The Investigation: Do We Have Backup? (Checking Indexes!)
Alright, Query Optimization 101: If a query filtering on a column (account_id in my case) is slow on a huge table, the first suspect is usually a missing index. So, I went digging.
Aha! We did have indexes:
event_logs_account_id_event_time_idxon(account_id, event_time)- Okay, helpful for theWHEREclause, but doesn't help with thesession_keyoruser_tagpart.event_logs_pkeyon(account_id, session_key, user_tag)- Wait a minute... Primary Key? Unique index? On all three columns involved?
(Lightbulb flickering on)

The Eureka Moment: The Primary Key's Superpower!
This is where my dusty college notes suddenly felt relevant! Specifically, that Primary Key guarantee is a direct example of the 'C' for Consistency in ACID properties - ensuring the database state always respects the defined rules and constraints.
A Primary Key (or any Unique Index) guarantees that the combination of values in its columns is unique across the entire table.
Our primary key is on (account_id, session_key, user_tag).
Let's think about this:
We are filtering for one specific
account_id.For every row matching that
account_id, the combination of(account_id, session_key, user_tag)must be unique.If the
account_idpart is the same for all these rows... what does that mean for the remaining(session_key, user_tag)part?
It means (session_key, user_tag) must also be unique within that filtered set!
If we had two rows for the same account with the same session_key and user_tag, it would violate the primary key!
My COUNT(DISTINCT (session_key, user_tag)) was completely redundant! I was asking the database to do a whole lot of extra work to find uniqueness that was already guaranteed by the table structure itself!
The Fix: Embrace Simplicity!
Realizing this, the fix was laughably simple. If every row for that account already represents a unique (session_key, user_tag) pair, I don't need to find the distinct pairs... I just need to count the total number of rows for that account!
SQL
-- The Gloriously Simple & FAST Query
SELECT
COUNT(*) -- Just count all the rows matching the account!
FROM
event_logs
WHERE
account_id = 'some_specific_account_id';The Result: Blazing Speed! (3.2 Seconds!)
I ran this new query, holding my breath... and BOOM!
3.2 seconds.
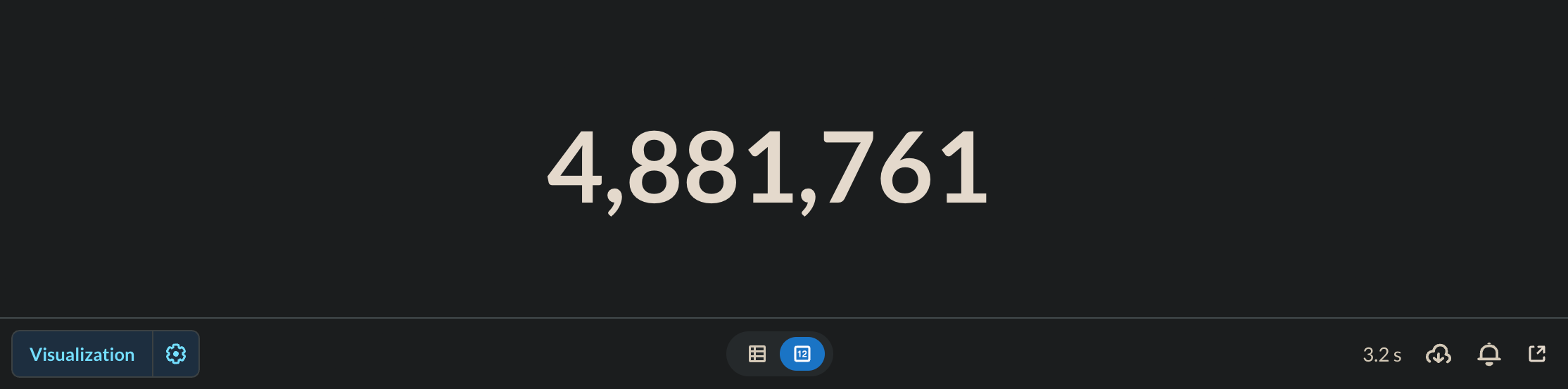
From 43.3 seconds to 3.2 seconds. That's nearly 13 times faster! All by removing one seemingly innocent DISTINCT.

The Science Bit: Why is DISTINCT So Demanding?
So, why was DISTINCT slowing things down so much? Is it evil?
Not at all! But it is hard work for the database. To find unique rows/values, Postgres usually has to:
Gather all the matching rows (potentially millions in my case, even after filtering by
account_id).Either Sort all that data based on the distinct columns and then pick out the unique ones.
Or Hash each row/value into a temporary table in memory, checking for duplicates as it goes.
Both sorting and hashing huge amounts of data take significant CPU time and memory. If it needs more memory than allocated (work_mem setting in Postgres), it starts using the disk, and performance plummets dramatically.
In my first query, the database was likely doing a massive sort or hash operation on all the (session_key, user_tag) pairs for that account only to arrive at the same number, COUNT(*) would have given instantly (well, almost instantly!). We were saved because the primary key let us skip that whole expensive process.
The Takeaway: Know Your Constraints!
This whole adventure was a powerful reminder:
Understand Your Data & Schema: Constraints like Primary Keys and Unique Indexes aren't just for data integrity; they provide valuable information the query planner can use (and that you can use to write smarter queries!).
Question Your Assumptions: The "obvious" query isn't always the best.
DISTINCTseemed logical, but the context of the unique index made it unnecessary.Indexes are Your Friends: While the primary key was the hero here, proper indexing is fundamental for database performance, especially on large tables.
DISTINCTis Powerful but Costly: Use it when you need it, but be aware of its performance implications and double-check if it's truly necessary.
So, next time your query feels sluggish, take a moment to revisit your table structure, your indexes, and your constraints. You might find, a simple key (pun intended!) unlocks massive performance gains.
Have you had similar "Eureka!" moments optimizing queries? Share your stories in the comments below - let's learn from each other!
Happy querying!
Great lessons for a newbie to SQL, like me. Thanx @aditya